深度學習基礎─Regression
一、什麼是 Regression
Regression(中文:迴歸)是一個非常基礎的監督式學習,應該也是每個人第一個會接觸到的機器學習演算法吧。
Regression簡單的定義就是我們設計一個function,根據輸入的資料預測一些數值,這樣的function我們稱之為Regession function。
Regression的常見應用在像是股市的預測、消費者是否願意買某項產品這類的問題。
二、Regression function的設計
不論是什麼樣的機器學習演算法基本上都不會超出三個步驟
- 設計model
- function的優化
- 找出最優的function
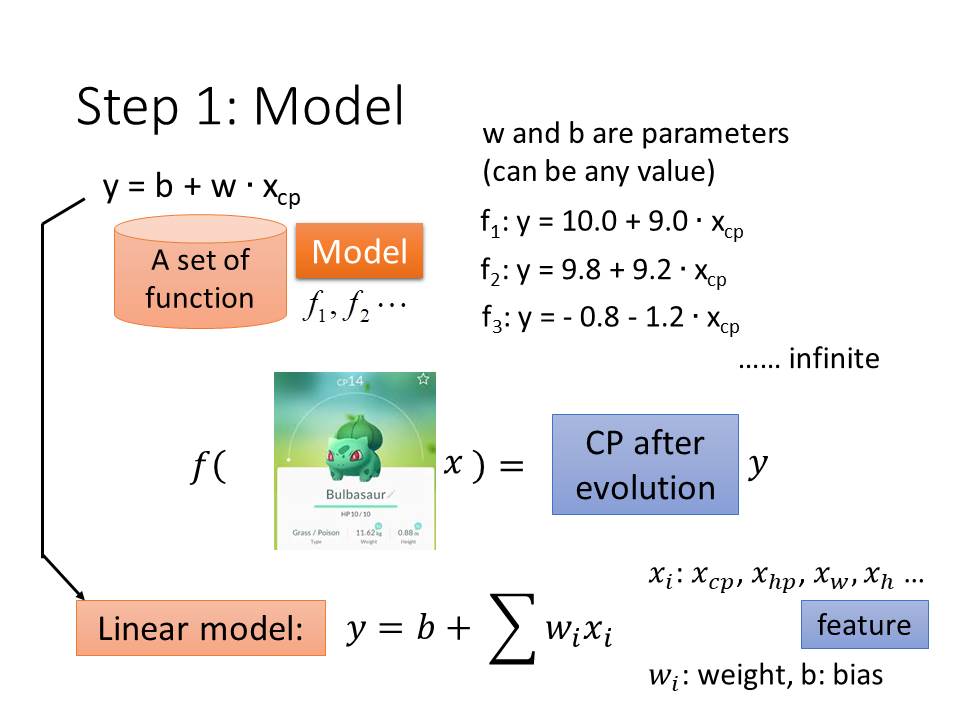
第一步:設計model。
所謂的model就是很多個數學式的集合,透過這個數學式的集合我們可以順利的預測的我們要的值。
這些式子一般最基礎版本就是wx+b(其實就是一元一次方程式啦),不過我們必須要根據情況更換成別的function,例如資料分布看起來像二次方程式,我們最好得把function替換成二次方程式;有N個特徵值(feature)就將它換成N元一次方程式等等。
第二步:對function進行優化。
在設計好model之後我們就要來優化它啦!
在談論優化問題前我們要先來談談什麼是監督式學習。
所謂的監督式學習就是我們得出題目(資料與model)考電腦,而電腦必須學習(調整model參數)以得到好的成績(高正確率),不過如果題目出錯(不論是資料或是model)就不會有正確答案。
機器學習的優化方法就是設計一個 loss function 計算每一筆資料的誤差值,而計算方式有許多種,而最常見的是最小平方法。
我們可以假定每筆資料都是一個座標(X , Y),X就是我們輸入的feature,Y就是他的值。至於為何最小平方法可以找到最小的loss呢?我們可以參考這一篇文章。
第三步:選擇最優的參數
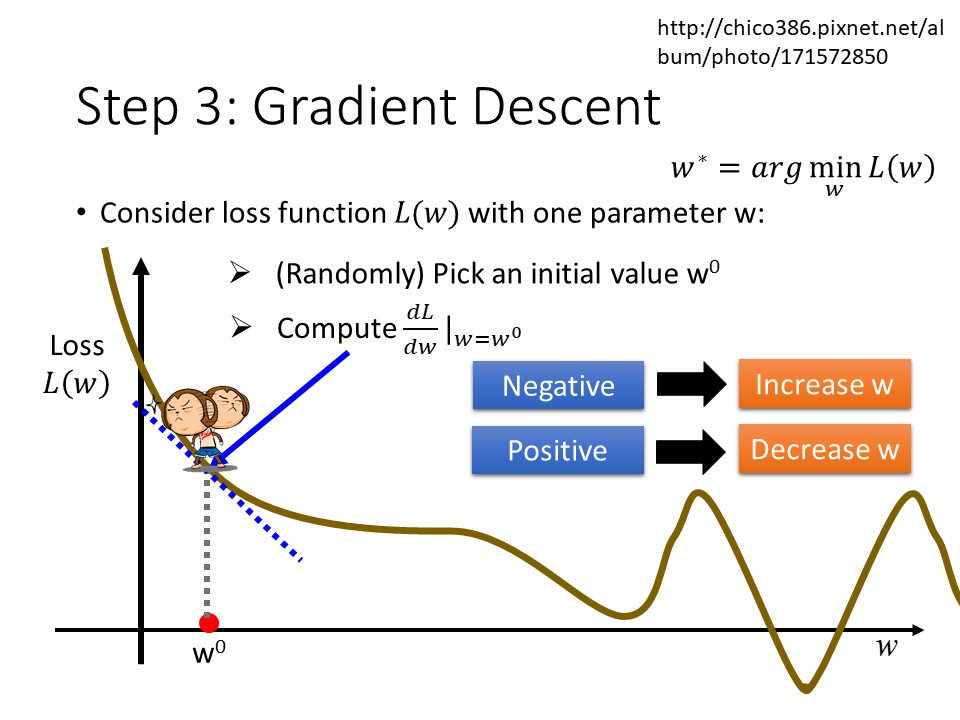
在尋找最小的loss的過程中,我們可以用暴力法去把每一個w和b算出來,透過暴力法也許我們可以找到一個Global minimun (最佳解),但是因為w跟b有無限多個,也許等到天荒地老我們也沒辦法找到它,因此我們將會採用一個方法叫做Gradient Descent。
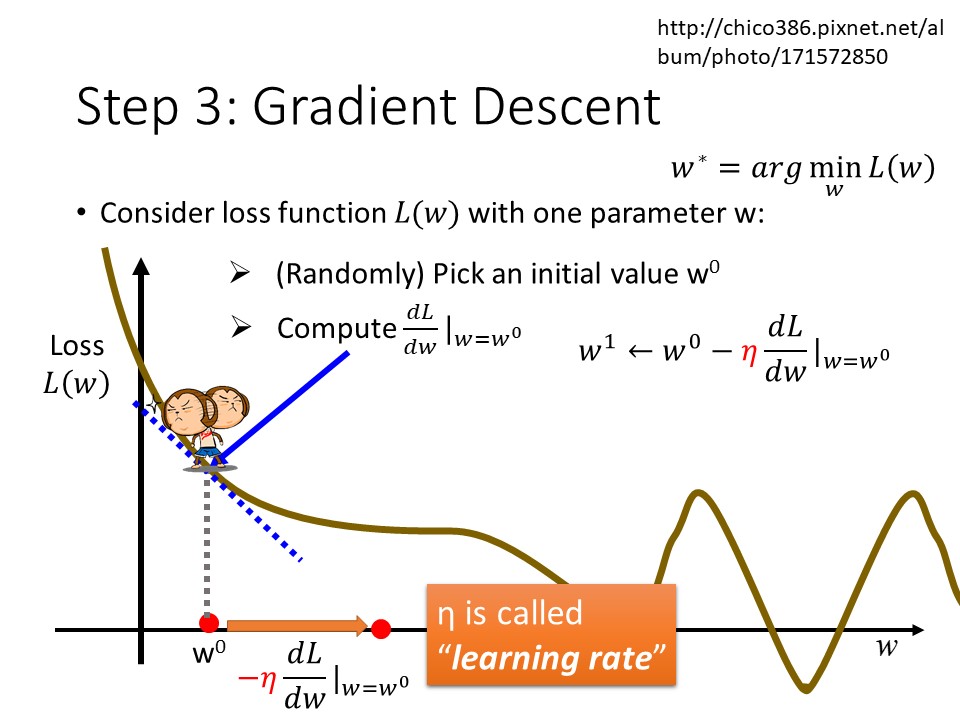
Gradient Descent的方法就是一開始先將loss function的參數隨機設定成W0,接著我們對參數w做微分便可得到當前loss function的斜率,若斜率為負,我們增加W0;若為正,就減少W0;斜率的絕對值越大,那麼更新的速度就會越快,Gradent Descent會一直重複上述動作做直到微分值為0。
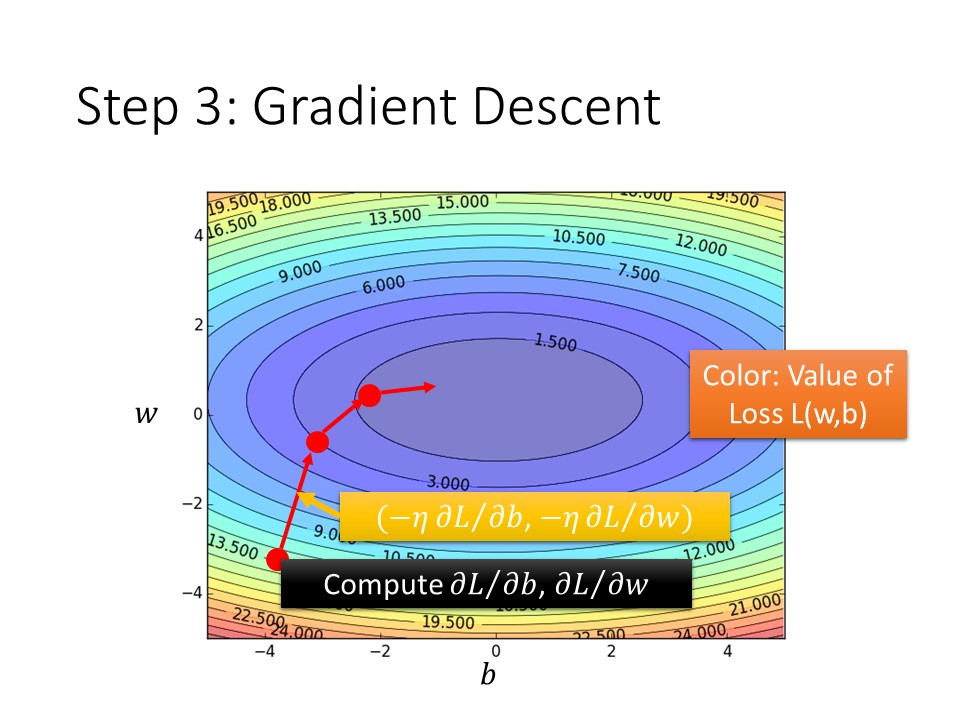
將上述的中文敘述寫成數學式就會變成這張投影片,而投影片的紅色標注的常數就是Learning rate,這個常數會決定每一次更新要讓function走多長的距離。
我們把loss function的分布圖畫成一個二維的圖就會長的像上面這樣,紅色的線就是做Gradient Descent後的得到向量(Gradient),Gradient就是loss的法線向量,當我們一直重複做Gradient Descent就會前往最中間的點也就是local minima。
如果看不懂可以看莫凡的影片,看完之後對Gradeint Descent的運作就會有比較好的了解。
Gradient Descent 可能遇到的問題以及改善
Gradient Descent確實很棒,但是它並不是沒有缺點的,下面我們將會探討Gradient Descent會遇到什麼問題,並且如何改善。
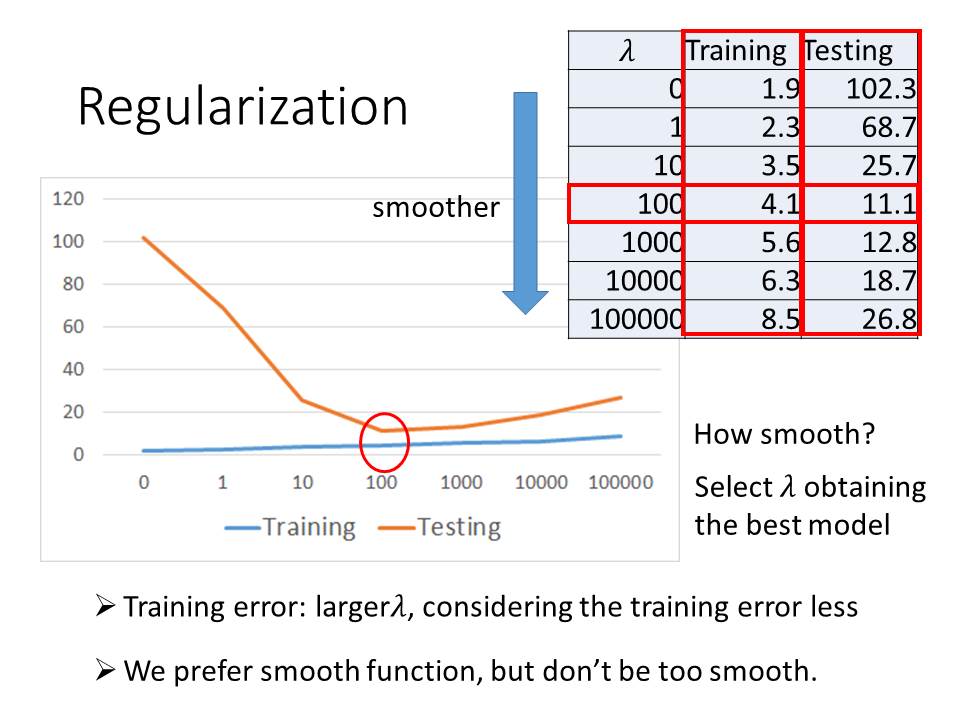
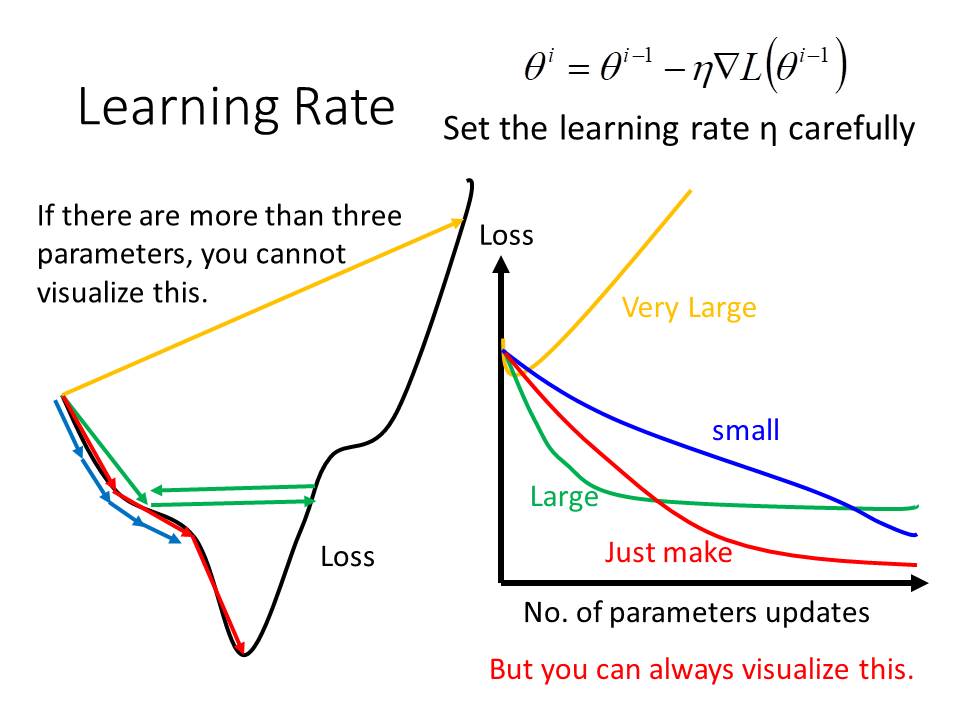
1. 要如何決定Learning Rate的值?
Learning rate對於Gradeint Descent來說是一個相當重要的參數,如果Learning rate過大(如黃線或是綠線),那麼就會產生震盪的情形,甚至無法讓loss收斂;如果Learning rate過小(藍線),就會要花很多時間才能找到local minima。
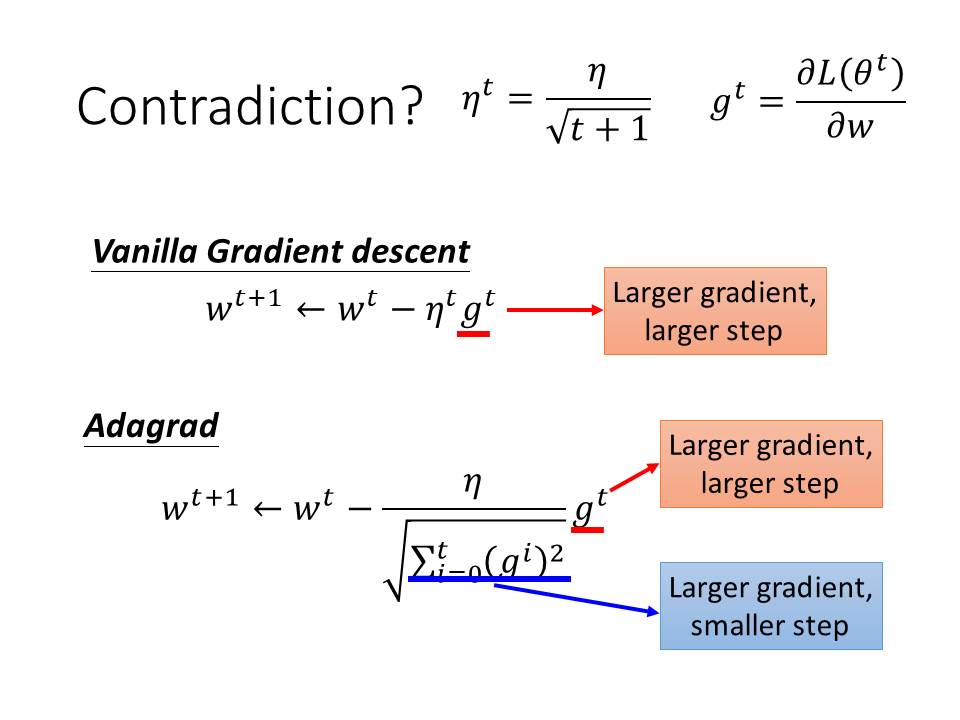
為了解決這樣的問題,我們可以將Learning Rate設計成動態的,其中一個演算法就是Adagrad。
Adagrad的原理就是對於每一個參數我們都會給他一個它專屬的Learning rate(例如W0有一個Learning rate R0,W1有R1等等),Adagrad計算的方式為:將learning rate除以loss function的微分值平方後相加後算出平均值最後取平方根(下面的公式),如此一來Gradent 越大,我們每一次走的步伐就越小。
2. 如何使Gradient Descent的速度加快?
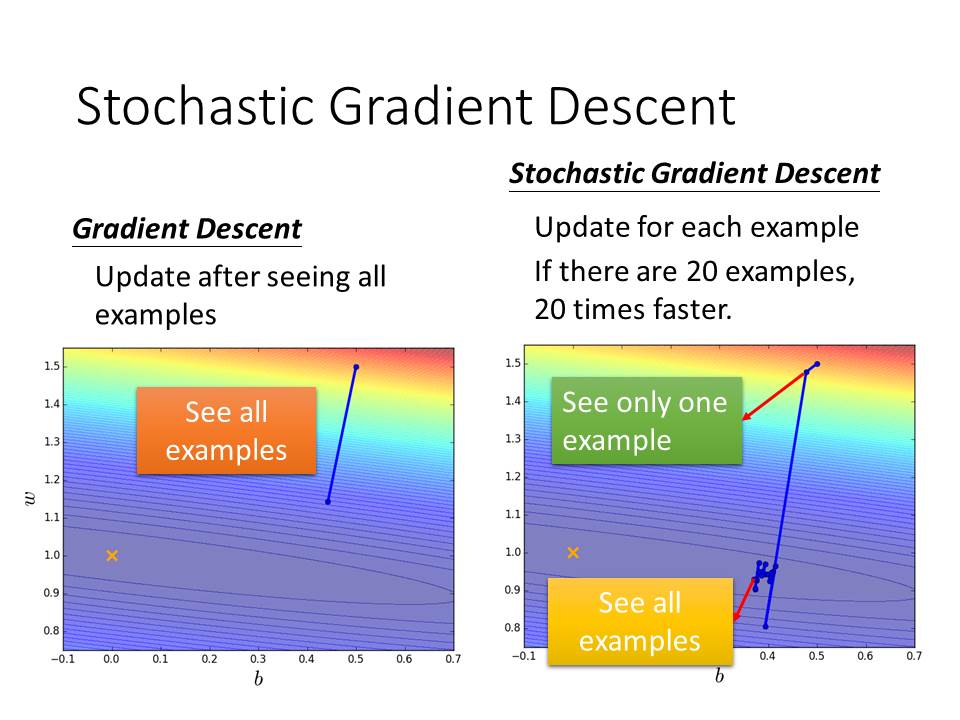
在原始的Gradient Descent中,我們會先把所有的資料做完loss後才做Gradient Descent,但是這樣其實速度有點慢,因此就出現一個改良的方式叫做Stochastic Gradient Descent。
在Stochastic Gradient Descent中,我們跑一個data就做一次Gradient Descent ,如果有20份data,就會跑20次Gradient Descent ,這樣一來速度就會快很多很多。
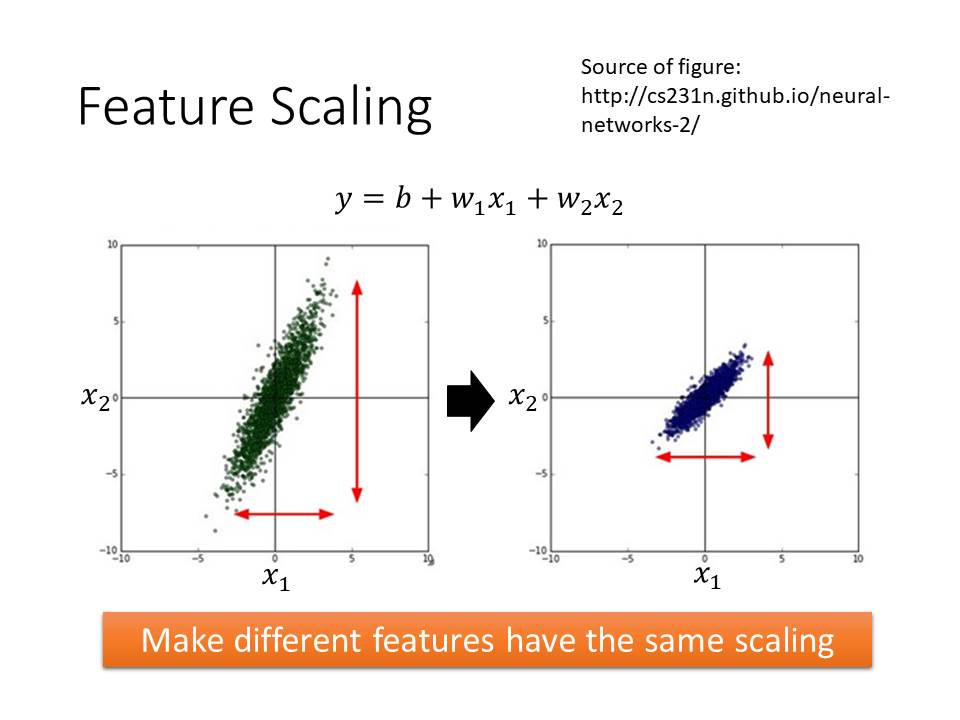
另一個方式是做Feature Scaling,也就是預處理。
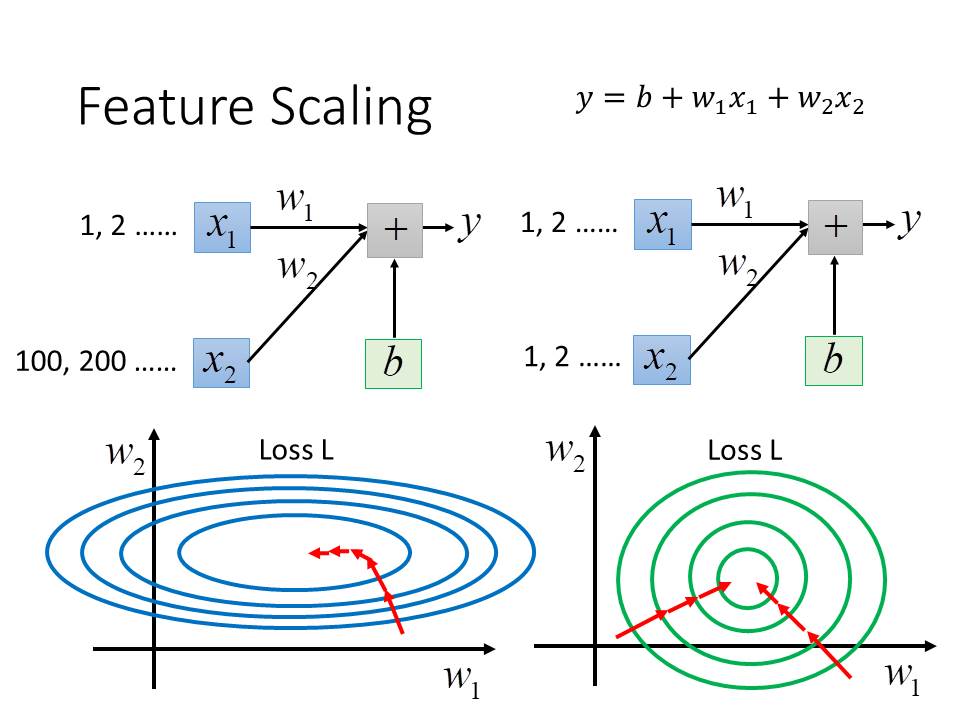
有時候不同的feature之間的值會差異很大,例如X1=1,2,3....,X2=100,200,300,在這樣的情況下對於我們做Gradient Descent是相當不利的。我們可以觀察上面這張圖,在尚未做Scaling的時候Loss function的圖形是一個長橢圓形,Gradient一開始候並不會指向圓心(local minima),在這樣的情況下如果我們不做Adagrad會很難得到local minima,因此我們必續對X1與X2做一些手腳讓他比較容易被計算。
在經過適當出處理後,loss function就會如右邊那張圖是正圓形,每一次的Gradient都能夠確保走向local minima。
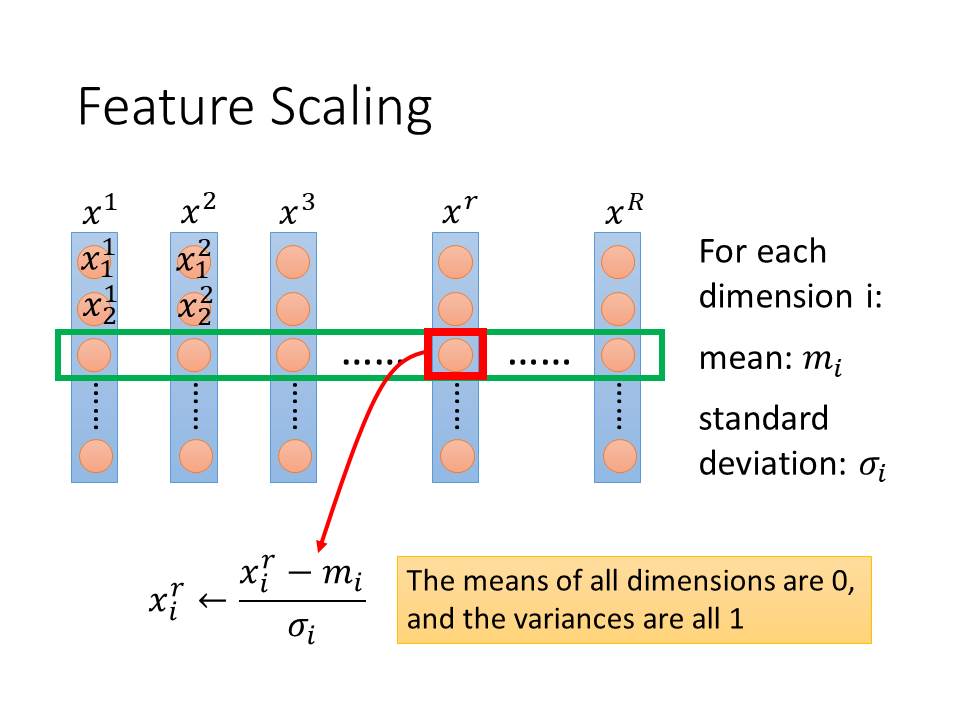
接下來要講解Scaling的方式。
假設我們有R個feature,並且每一個feature都有i個資料,對於每一個dimension i 的feature我們要去計算出第i個平均值以及標準差,
而新的feature就會是第R個feature的第i個資料減掉第i個平均值再除以第i個標準差。
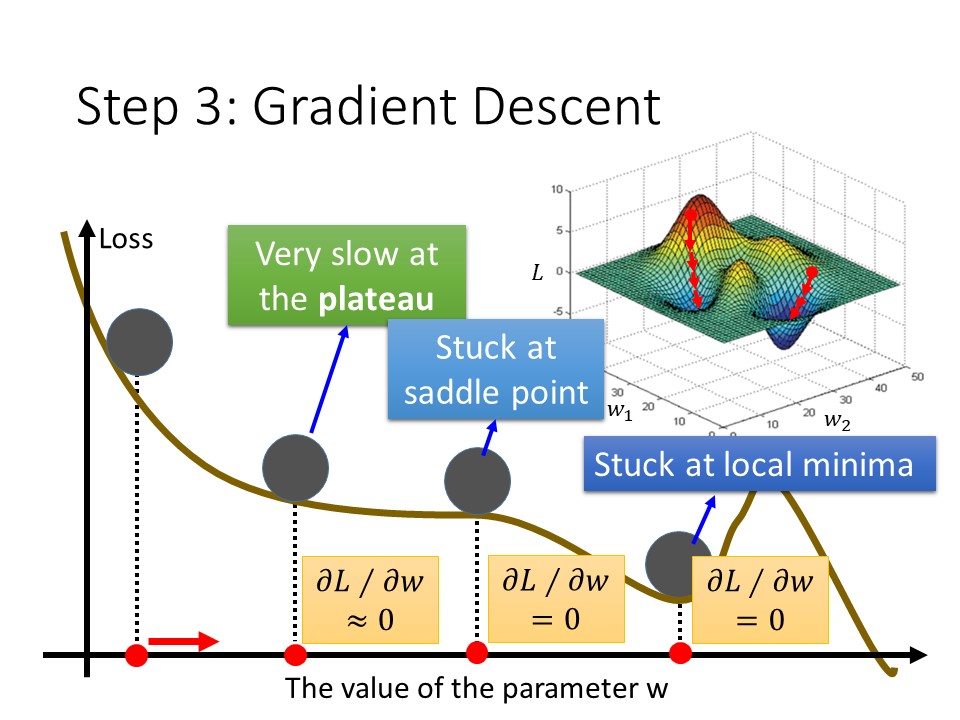
3. 微分=0就一定是Local minima?
並不是每一次微分=0的值都會是最低點,在saddle point的微分值也是0,但是saddle point 卻不是 local minima,以上突來說其實它比較像是反趨點,另外在非常接近local minima的時候更新速度會相對慢很多。
由於Gradient Descent沒有辦法找到 Global Minima,因此我們只能多做幾次訓練找到最好的model。至於model如何選?下一篇文章將會有進一步的講解。